
We have created a new sister database to the main Guide to PHARMACOLOGY (GtoPdb) – SynPharm, a database of drug-responsive protein sequences.
Each sequence in SynPharm is derived from a GtoPdb interaction. In each case we have identified the continuous protein sequence within the receptor chain that facilitates that interaction, and provided structural, visual, spatial and affinity data.
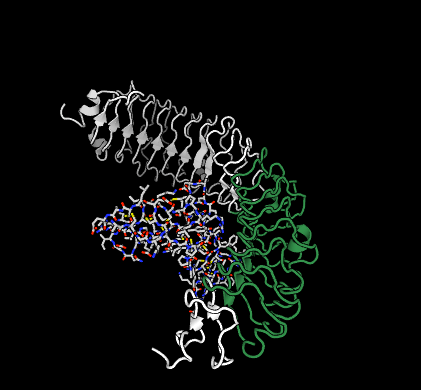
A peptide ligand (R-spondin-1) bound to its receptor (LGR4), with the bind sequence highlighted in green. See its page for more details.
Bind Sequences
Each sequence in the database represents a potentially ligand responsive protein sequence. In addition to providing a pharmacological reference as to the portion of protein chains which actually mediate their interactions with drugs, it is also hoped that SynPharm could act as a library of transferable protein modules to synthetic biologists, enabling the drug responsiveness to be conferred to a protein of choice.
In order to allow researches to assess the likelihood that a bind sequence (as the drug responsive elements are termed) will function in isolation, certain metrics are provided. We provide a ‘contact ratio’ – the ratio of internal contacts (all non-hydrogen atom pairs within the sequence within 5 Angstroms of each other, excluding atoms within two covalent bonds of each other) and external contacts (all non-hydrogen atom pairs between the sequence and the rest of the chain, less than 5 Angstroms) – and a distance matrix to show the ‘globularity’ of the sequences. Each sequence also contains a manipulable 3D visualisation of the sequence in question.

A example of a residue distance matrix. The bind sequence is represented by a dotted black line within the context of the protein chain it derives from.
In addition, we provide pages for each of the ligands that interact with a sequence, along with a small selection of the data on the ligand from the main Guide to PHARMACOLOGY database.
Creating the Data
Each interaction in the Guide to PHARMACOLOGY was mapped to one or more PDB files where possible. Some already had PDB information, and where this was not the case, the RCSB web services were queried by SMILES, InChI, name and peptide sequence (in the case of ligands) and accession number (in the case of targets) to identify more. In total, 704 interactions mapped to at least one PDB code, and after manually removing some false maps, this came down to 672. Though a relatively small proportion of the 15,000 or so interactions that GtoPdb contains, it is merely an indicator that most interactions observed have do not yet have high quality structural data.
Each interaction-PDB map was turned into a sequence by first identifying the HET code and ID of the ligand within that PDB file (generally provided by the PDB REMARK records), then identifying the residues that facilitate binding (again most PDB files already annotate this but in cases where this is not true, atomic distances were used to identify probable residues), and then using these to construct a continuous sequences. Not all maps were suitable to this – some had binding sites split across multiple protein chains, and yet more contained too many missing residues – residues flagged as missing from the crystallographic (or otherwise) experiment from which the PDB was derived. Ultimately 540 interactions had at least one PDB map that could be used to create a sequence.
It is expected that the SynPharm database will grow as the principle Guide to PHARMACOLOGY database is updated – or indeed as further structural data is added to the PDB database pertaining to interactions already documented.
A summary of the current data can be found at synpharm.guidetopharmacology.org/about/data.


Leave a comment